Enabling Astronomy Image Processing With Cloud Computing Using Apache Spark
Zhao Zhang
My name is Zhao Zhang, I am a joint postdoctoral researcher at AMPLab and Berkeley Institute for Data Science, University of California, Berkeley. The theme of my research is to enable data-driven science with computer systems.
This case study describes the process of building Kira, a distributed astronomy image processing pipeline in the cloud environment. The idea of the Kira project is to explore the applicability of cloud computing based software stack in supporting scientific applications. Specifically, we use the SEP (Source Extraction Python) library for domain computation. We choose Apache Spark and Hadoop to build the infrastructure of distributed processing and data storage.
Workflow
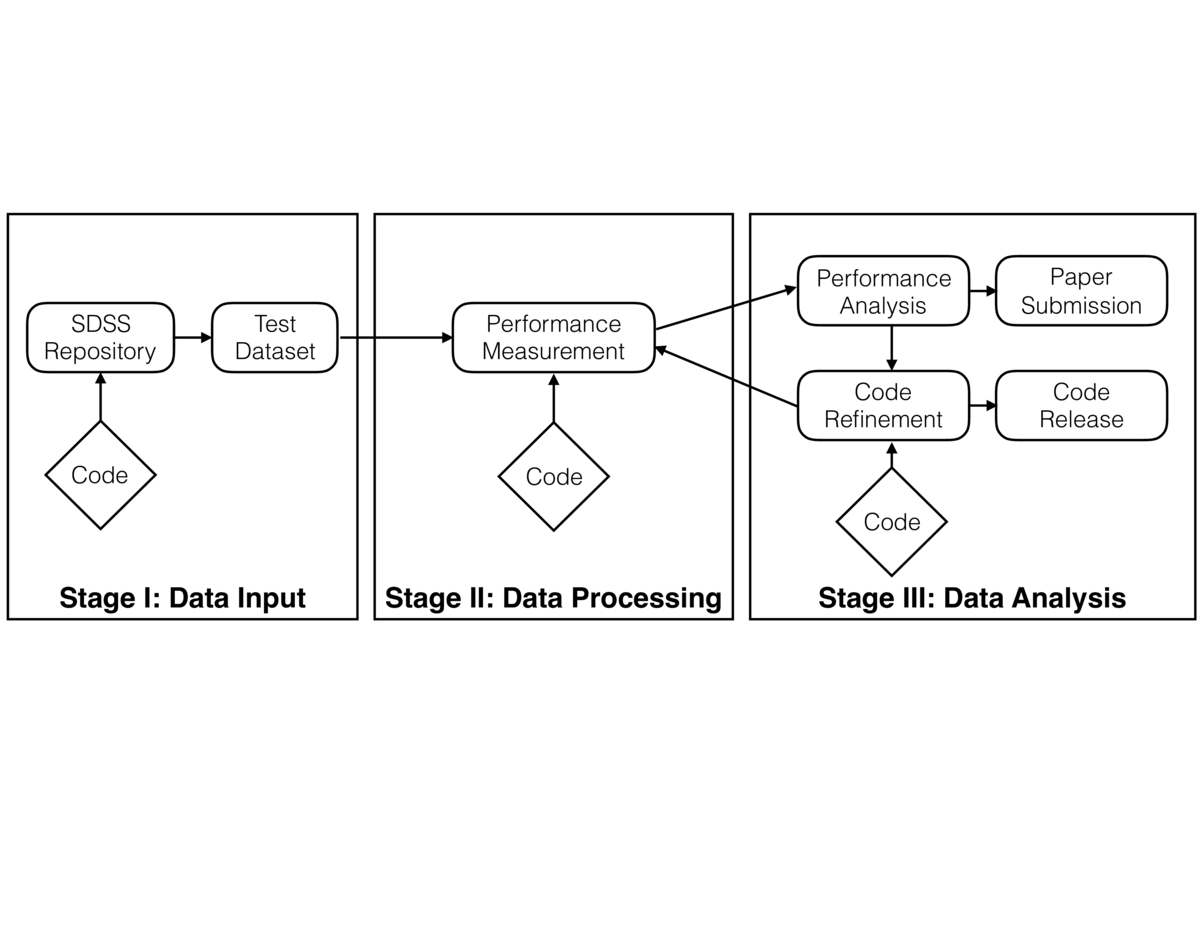 We use LaTeX and Slides to track the merit evaluation: why do we need a new system for astronomy image processing, what makes it a better system, and what lessons we can we learn from this research.
We use LaTeX and Slides to track the merit evaluation: why do we need a new system for astronomy image processing, what makes it a better system, and what lessons we can we learn from this research.
We use a private GitHub repository to keep track of solutions for technical barriers such as I/O processing, Spark interaction with C program, Spark system parameter configurations and many others.
The whole system is built with multiple programming languages and tools. At the programming language level, we use Scala, Java, Python, Bash, and C. At the system level, we use Spark for task coordination, HDFS for persistent storage, and the SEP library for actual computation.
The source code of the project is kept in a public GitHub repository to make it open source.
The manuscript is being kept in a private GitHub repository since it is under review.
In system design phase, we decided to use three datasets four development, testing and performance measurements. But we end up with four datasets. A trivial dataset that contains only a few image files is used for development and testing. A small dataset (12GB) is used for quick verification at scales. A large dataset (65GB) is used for large scale performance measurement. A fourth dataset (1TB) is used to show the data processing capacity of the Kira system as we put up the paper.
All these datasets come from the Sloan Digital Sky Survey. Some of them are from Data Release 2 while some are from Data Release 7. We choose them arbitrarily as we care more about the system capacity rather than the science in this research.
Our collaborators are: Kyle Barbary, Oliver Zahn, Saul Perlmutter are astronomers. Frank Nothaft, Evan Sparks, Michael Franklin, David Patterson are experts about Spark and cloud computing in general. Zhao Zhang has rich experience in HPC community and some experience in cloud computing as well as a bit astronomy background.
We use private GitHub repository for manuscript management and public GitHub repository for project management.
We have summaries for Team Brainstorming and Merit Evaluation phase. System Design's output is in the form of figures and is kept in GitHub repository. Solutions for Technical Barriers are kept in a private GitHub repository. Documents, Source code, system configurations as the products of coding/testing/tuning/measurements are kept in a public GitHub repository. The paper draft is kept in a private GitHub repository.
Before explaining the details of the diagram, I will first briefly review the software and systems that are used in this case study.
FITS (Flexible Image Transport System) is a widely adopted image format in the astronomy and cosmology community. It is a fixed format with the image metadata as text and the actual image as binary format.
SEP (Source Extraction Python) is the software that detects light source objects from images. It rewrites the SEXtractor software by exposing primitive functionalities through a library interface with both C and Python.
Apache Spark is a popular distributed computing framework in cloud computing. It offers implicit parallelism and the lineage-based fault tolerance through the Resilient Distributed Dataset (RDD) abstraction. Spark is built using the Scala programming language which compiles a program that is executable on Java Virtual Machine (JVM).
JNI (Java Native Interface) provides a method to call existing C libraries inside a Java/Scala program. C and Java/Scala data structures can be used to exchange information between the two runtimes.
Amazon EC2 (Elastic Compute Cloud) is a public cloud service provided by Amazon. Users can request a number of compute nodes with various hardware and software combination.
Amazon S3 is a data storage service provided by Amazon. Users can host there dataset on S3.
NERSC (National Energy Research Scientific Computing Center) is a high performance computing facility operated by Lawrence Berkeley National Lab. It hosts a few supercomputers and clusters.
SDSS (Sloan Digital Sky Survey) is a large scale sky survey, its data is publicly available online.
Thread safety is an operating system concept that describes the concurrent execution of multiple threads safely manipulating shared data structures.
The process begins with team brainstorming of how modern computer software and hardware can accelerate the astronomy image processing pipeline. This requires a wide and also deep understanding of the state-of-the-art research and technical solution. In this research, we gather domain expertise (astronomers), cloud computing expertise and high performance computing expertise. We review the existing work and we think using cloud computing software-hardware stack can improve the overall application performance, but we have no idea by how much it can improve. The research is an exploratory process to implement the idea and quantitatively measure the improvements if there is any.
The Team Brainstorming and Merit Evaluation phase happened back and forth as we keep asking why are we building such a project. Detail questions include: What are the existing solutions? How does the new project make difference in terms of performance and usability? Who are the potential users? This procedure lasts for about two weeks, all members of the Kira project are involved in the discussion. The pros and cons of each existing solution was documented, and later used in the paper.
The System Design phase lays out the programming interface of Kira, the modules and interactions between the modules. In this phase, we also identify some technical barriers of this project. I am listing them below, feel free to contact me if this is hard to understand:
Kira I/O, how to make Spark read FITS images
Calling C library in Spark, how to make Spark work with existing C code in the SEP library
Setting up compilation environment, set Maven to automatically build Kira
As we progress with the code, we notice a few other technical barriers:
Thread safety, neither the jFITS library nor the SEP library is thread safe
Load imbalance, scheduler tuning for this particular workload
For each of these technical barriers, we seek solutions for them. The solutions come from three sources: colleague expertise, google, and documents. By isolating the barriers, we were able to focus on a single barrier each time and can quickly verify the solution. The resulting code is stored in GitHub, and later merged into the project. This process takes about two weeks.
The Software Coding and Testing phase takes about three weeks, we managed to integrate the SEP library through Java Native Interface with Spark, thus finally implement Kira. I implemented the code, and wrote the documents to make it convenient for my self to repeatedly run experiments. In the meantime, I prepared four datasets for performance measurements. A 24MB (4 files) dataset for sanity check, a 12GB (2,310 files) dataset for small scale test, a 65GB (111,50 files) for medium scale test and a 1TB (176,938 files) for large scale tests. The datasets were initially stored in NERSC shared file system, later I made a mirroring on EC2 S3 service, as most experiments were run on EC2 where S3 has a better transfer bandwidth to.
Performance Measurements and Performance Tuning come in pair and we go back and forth frequently. The key thing in these two steps is that we need a reasonable expected performance before the measurements. If the measurement does not match with our expectation, we need to analyze the reason and tune the system. Our methodology is like this: we started on 1 core on a single machine. We compare the Kira performance against the equivalent implementation to understand the slowdown introduced by Spark and JVM. Then we started to scale up with more cores on the same node, and observe the scaling curve. By doing that we understand the bounding factor of the performance on a single node. Later on, we scale out on multiple nodes by doubling the number of compute nodes in each step and observe the performance scaling. Since Spark hide the scalability complexity in the system, all we need to do here for different scale is to set relevant parameters in the configuration files. The code and documents are kept in GitHub, and the dataset is kept in Amazon S3 service.
With all of the scripts from Merit Evaluation, System Design, and Source code, we put together the paper. Writing the paper is a collaborative process. We used a private GitHub repository to host the paper, and using Pull Request to manage everybody's editing.
Pain points
- (reproducible results) For the results to be reproducible, the readers should be able to tell and access the computers with the same hardware, the code base used particularly for the experiments, the dataset that was used for performance measurements.
1.1 Hardware access. Since we are using Amazon EC2 resources, the same computer hardware is mostly accessible unless Amazon upgrades the hardware. It happens every few years. A second risk is that for large scale test, the reader might contact Amazon to increase the hardware limit which Amazon uses to limit the quantity of resources each user can posses at the same time.
1.2 Code base. We maintain our code under a public GitHub repository, so it is accessible to all. However, the pain point is that the software evolves and the performance might change with the software evolution. Thus it is important that the authors should let the readers know which version of the software is related to the results that readers care about.
1.3 Dataset. The astronomy image dataset we use is Sloan Digital Sky Survey Data Release 7, which is publicly accessible. As long as the data hosting service is up running, the dataset is available. We also make a copy of the dataset we used in Amazon S3 service with public accessible permission. The pain point is that we have to pay Amazon for maintaining the 1TB dataset, and eventually we will run out of funding, so instead we have to publish the dataset file list as a text file in the code base.
Key benefits
I break this question down to two: non-usable workflow and non-reproducible workflow.
Non-usable workflow. I have seen a couple of projects in astronomy, where the authors conducted study on applying new tools to solve the old problems, but the authors failed to publish their source code along with the paper. This gives up the opportunity for people to build solutions upon their work. For Kira, we make the source code available on GitHub, so people can extend this code base for more functionalities.
Non-reproducible workflow. There was one experiment I read in a paper that I would like to reproduce, and design a new solution for it. However, the experiment was not reproducible due to the software version evolution. During the Kira building process, we particularly care about this issue, we documented the hardware, code base and dataset that are used for the performance measurement, so any user that follow the documented instructions should be able to reproduce the results.
Key tools
GitHub for code management, and Amazon S3 service for data hosting. We built Kira with Apache Spark which is a highly active open source project, so that we do not have the concern of the computing framework is out of maintenance if our academic funding ends.
Questions
What does "reproducibility" mean to you?
In the context of my case study, reproducibility has several levels of meanings. The very baseline is that users can compile the source code and pass the tests. Secondly, users should be able to configure the computer cluster so the can reproduce the performance in the documents. Since it is impossible to reproduce the exact performance measurement for every single run, a statistical repetition should be fine (average performance with bounded variation). Generally for computer system research that involves data, a public available data source is necessary for the performance to be reproducible.
Why do you think that reproducibility in your domain is important?
As computer system researchers, we build systems assuming people will use them. So it is important that people can follow the instructions in the documents to reproduce the state in which the system works. And it is important that users can reproduce the improvements over existing systems we describe in the paper or documents so they are more likely to adopt our systems. As paper reviewers, it is more convincing if they can reproduce the results in the paper as these are the evidence of the paper's idea.
How or where did you learn about reproducibility?
I learned the reproducible practices since the first time I submitted my homework project in college and ever since. I need to write a README file along with my code so the teaching assistant could compile and run my code to test if my solution is right. The later research experience follows the same path.
What do you see as the major challenges to doing reproducible research in your domain, and do you have any suggestions?
I used to design systems on supercomputers, where many people including paper reviewers have no access to. Thus, it is impossible for the research to be reproducible.
Another major pitfall is due to software version evolving. At the time of writing the paper, some features of a piece of software was working, and the researchers measured and published the numbers. But these numbers are no longer reproducible after a few versions.
What do you view as the major incentives for doing reproducible research?
I break this down to reproducible results and reproducible research process.
4.1. (reproducible results) The systems I build are usually to facilitate scientific research. The systems either expedite the execution of computer programs or provide novel functionalities (e.g. failure diagnosis). To make sense about my research, users should be able to see the performance improvement I documented in the paper or documents. They should be able to use the novel functionalities to ease their research. So reproducibility of the systems is the key to prove the system actually works.
4.2. (reproducible research process) As a whole process, this particular research case is exploratory. We only have a conjecture about the performance before the implementation and measurement. I am not familiar with the tools I am using also (Apache Spark, Scala, Java Native Library, SEP library, Source Extractor C program). I think (not quite sure) the incentive for the reproducible research progress is helpful in my future projects. Once again, if I am facing such situation, I know where to start to tackle a complicated problem. My methodology particularly for this research is: 1) a more-or-less valid hypothesis, 2) a performance profile of the existing solution, 3) isolating the technical barriers, 4) solving the technical barriers, 5) build the new solution, 6) performance measurement and tuning.
Are there any best practices that you'd recommend for researchers in your field?
I would recommend for open source software and related publications. The authors should maintain a version of the software for readers to reproduce the results in the paper. These versions and repository should be included in the paper.
Would you recommend any specific resources for learning more about reproducibility?
I can only think of GitHub for code management and Amazon S3 for data management right now.