Estimating the Effect of Soldier Deaths on the Military Labor Supply
Garret Christensen
My name is Garret Christensen. I am currently a project scientist at the Berkeley Initiative for Transparency in the Social Sciences and a fellow at the Berkeley Institute for Data Science. I work on questions of program impact evaluation in labor and development economics. I conducted the research described below as part of my dissertation work in economics at UC Berkeley, beginning in 2010. This research is on the effect of deaths of US soldiers in Iraq and Afghanistan on military recruiting. I use panel data methods with fixed effects to try and identify the causal impact of the death of a US soldier in Iraq or Afghanistan on recruiting in the soldier's home county.
Workflow
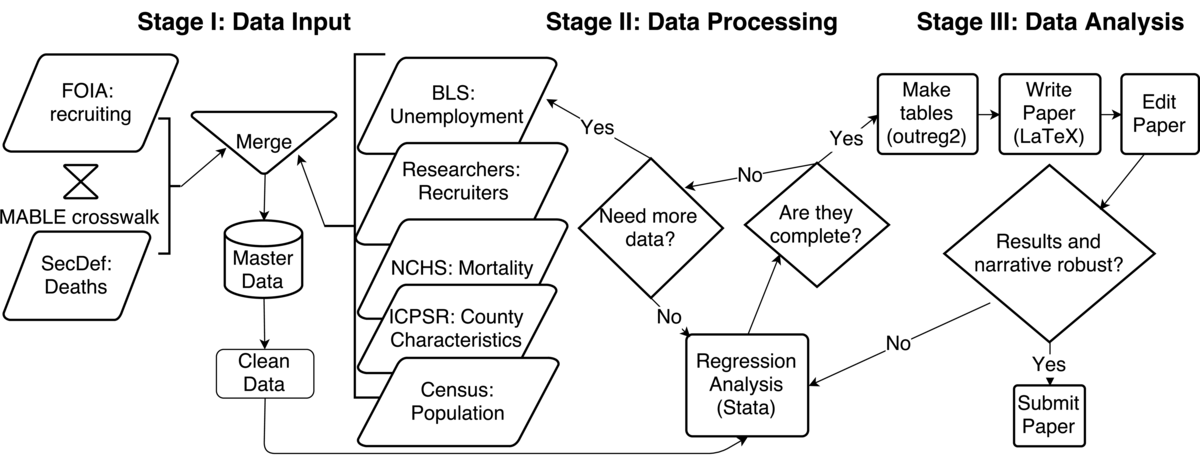
This project started with the idea, which I got from reading the newspaper, and hearing anecdotes about recruiting stations being overwhelmed after 9/11, and seeing popular reaction to the battle of Fallujah a few years later. The next step was obtaining the main data; a colleague just happened to have relevant data--the universe of US enlisted military recruits--through a Freedom of Information Act.
The other half of the main data is deaths of soldiers from Iraq and Afghanistan. I obtained this data from a public Defense Department website. Perhaps unsurprisingly, the original website is no longer operable. Luckily I still have, and have archived on Dataverse, the original dataset I downloaded and used. Updated versions of the data are also still available publicly. To merge the recruits and deaths data, I used Missouri Census Data Center's MABLE/Geocorr to construct a geographic crosswalk. This uses census geographies, so I used the 2000 Census version, but sadly I don't think I recorded every exact option used when constructing this crosswalk.
I used Stata to merge this data together as well as to do all subsequent statistical analysis. No, Stata is not open source, but it's what most economists use. I did all my work in script (.do) files, and with the 'version' command, theoretically any other user should be able to produce the same results. The code was version controlled, but only after a fashion by updating script files with the date as part of the file name. Old versions of files just got dumped into an archive folder, where they were kept permanently.
The merged data was analyzed using the xtpoisson (poisson) and xtreg (linear) regression algorithms in Stata. Regression tables were output to tab delimited plain text files using the user-written 'outreg2' command, edited in Excel, saved as .pdfs, and then included in the LaTeX file that made up my paper. Clearly, Excel is the antithesis of reproducible, but I didn't change numbers in the tables, just formatting. Next on my to-do list with the paper is to cut out this clunky step and do directly from Stata to LaTeX. I think the only reason I started out this way is because I wasn't comfortable enough with LaTeX to figure it out.
Regression output was by no means complete the first time. I looped back numerous times to add more data from other sources, such as the Bureau of Labor Statistics, the Cenus, ICPSR, etc. This would require updating the merging and analysis code, reformatting tables, and changing the text in the paper that refers to specific output. Unfortunately that process is still ongoing because the paper has yet to be accepted at a journal.
Pain points
Given that this research is based on observational data, and I did not pre-specificy my statistical analysis plan, I highly doubt that any other researcher who looked at my original raw data (or even my cleaned final data) would agree on the exact set of regression specifications that I should include in my paper. For the sake of transparency, however, I try to include a nearly-exhaustive set of alternative specifications in a lengthy appendix to the paper. For example, all the results are available using both log-linear and Poisson regression specifications.
Regarding the data, even though I am very grateful to staff at the Defense Manpower Data Center who provided me with the data, I'm less than confident that multiple identical FOIA requests for the exact same data would result in identical datasets, since I don't have access to the original data, and have no way to verify if the dataset I was given was the true universe of observations I requested. Perhaps that's just an issue with all original data--you'll never be able to go back to all the homes in the census and check their answers, but you do have the ability of downloading the data from the census server. I don't have access to the Defense Manpower Data Center's servers, but if I make available the data they gave me, does that mean we're reproducible? What if, as actually happened, you notice a completely implausibly low number of a certain type of observation in what is supposedly the universe of such observations?
Lastly, I'd say that my code is fairly well-documented, though it took a lot of work to get it there. Reading through it, I hope that other researchers could understand what the code is doing. There isn't yet a readme file but there is one master .do file that should (in theory) be able to reconstruct everything I've done from scratch. I have worked on the project for several years, with a few large breaks since economics journals can take 6 months to make decisions. I had to go back and extensively re-examine code that I no longer remembered. Having done that a few times, the code now seems fairly well-documented. This process would have been much easier had I kept a research log. I've had to open dozens of dated versions of the same file to find the last one written before a major change, which would have been much easier with version control or a research log. ### Key benefits
I would say that use of specific version control software is relatively new to the social sciences. When I began this work in 2010, I had never heard of git. I just used the method I learned from my adviser: include the date in the name of files, and every time you make significant changes to a script file (called a ".do file" in Stata), change the date. Using a distributed version control system (DVCS), as I do now, is a significant improvement.
Key tools
An excellent reproducibility tool to use is using the outreg2 (or estout) user-written commands in Stata to automatically turn regression output into journal-formatted tables. Although I use these commands, at present I have a clunky two-step process to first output the tables as .csv files before editing the formatting slightly then including the tables in my ultimate paper written in LaTeX. Ideal would be to use these commands to output the tables directly as .tex files, and include them in my paper file.
Questions
What does "reproducibility" mean to you?
Reproducibility to me is the ability of other researchers to get the same results as in my paper. In the weakest form, this would simply be for other researchers to be able to download my final datasets, run my final analysis code with nothing more than a file path name change or two, and get the exact results that are in my paper. A better version of reproducibility would be for other researchers to download my original raw datasets--the major two of which I have made publicly available using Harvard's Dataverse--redo my extensive merging and cleaning of data, and then get the same results. Even better would be for others to go through the same Freedom of Information Act (FOIA) request process from the Office of the Secretary of Defense that a colleague and I did, redo the merging, redo my analysis, conduct the analysis they themselves see fit, and get the same results. I have some concerns about that, which are described below, but I've done the best I can, and rest on the assumption that any missing data is not correlated in a way that biases my estimates, and that I was thorough enough in my analysis that my results are robust to other forms of analysis.
Why do you think that reproducibility in your domain is important?
Significant errors have been discovered in high profile published economics research. In one sense, economics is doing well because many top journals require data sharing, so it's actually possible for these errors to be discovered since replicators have access to data. But without a systematic replication or code-checking of analysis, we still don't know what fraction of research suffers from these problems. Should we throw out the baby with the bathwater? I don't think so, but we don't know right now.
Also, even when economists share their data, they very rarely share their raw data, and all of their cleaning code, and instead only share their final data and analysis. We're humans, so we're probably making some coding mistakes that go unnoticed.
How or where did you learn about reproducibility?
My graduate adviser Edward Miguel taught me the simple method of version control with file names while I was working on a project of his as a graduate research assistant.
What do you see as the major challenges to doing reproducible research in your domain, and do you have any suggestions?
A lot of the advances in transparency and reproducibility in economics are coming from the medical sciences, where randomized control trials are nothing new. But RCTs are still a very small minority in economics. Like my work here, most work is observational. Economics only created the AEA RCT Registry in 2013, and there has been no serious discussion of registration of observational work. Should we register observational work? Should we pre-register our statistical analysis plans for observational work? This is all uncharted territory in economics.
What do you view as the major incentives for doing reproducible research?
Being reproducible requires extra up-front costs. In the long run, the benefits should outweigh the costs, because when someone comes along and wants to extend or replicate my research, they won't find any embarrassing errors in my work.
Are there any best practices that you'd recommend for researchers in your field?
Comment the hell out of your code so you know what you were doing when a journal makes a decision on your submission after 6 months. Save all your analysis files using version control. Use a one-click workflow to incorporate your tables directly into your paper so you don't lose track of output.
Would you recommend any specific resources for learning more about reproducibility?
J. Scott Long's The Workflow of Data Analysis using Stata
My Manual of Best Practices in Transparent Social Science Research