pyMooney: Generating a Database of Two-Tone, Mooney Images
Fatma Deniz
My name is Fatma Deniz, I am a postdoctoral fellow at the International Computer Science Institute, Helen Wills Neuroscience Institute and a Data Science fellow at the Berkeley Institute for Data Science.
I use functional Magnetic Resonance Imaging (fMRI) and computational modeling to investigate how the human brain represents the world perceived through different sensory modalities. The current case study will only describe one part of my usual research pipeline, i.e., stimulus generation. Every successful neuroscience experiment needs to run several pilot experiments to create the best stimulus that is suitable for one or several questions that the researcher is asking. Hence, this step is usually tedious, where different parameters are tested until a final set of stimulus is used in the experiment. Ideally, the stimulus set is broad enough that new experiments (new hypothesis) can be derived using the same stimulus set. So, it is very important to provide access to the stimulus set that was used in a study, or provide the algorithmic procedure that created the stimulus.
In this case study I will focus on an image database that I created for a specific cognitive neuroscience experiment. These images have been used in several other experiments since the original paper was published. The images that I created for the study were two-tone, Mooney images. These images are binary, black and white images, where a single hidden object is only recognizable when the original image has been shown previously to the observer, the hidden object was outlined, or after a certain time when the observer intrinsically finds hints in the image that allows recognition. The image is not recognized immeadiately but after some time, which makes stimulus creation for a suitable experiment very difficult. Using these images in the original experiment (F. Imamoglu, Kahnt, Koch, & Haynes, 2013) I presented that functional connectivity in the human brain is altered when the hidden object is recognized vs. when it is not recognized.
Workflow
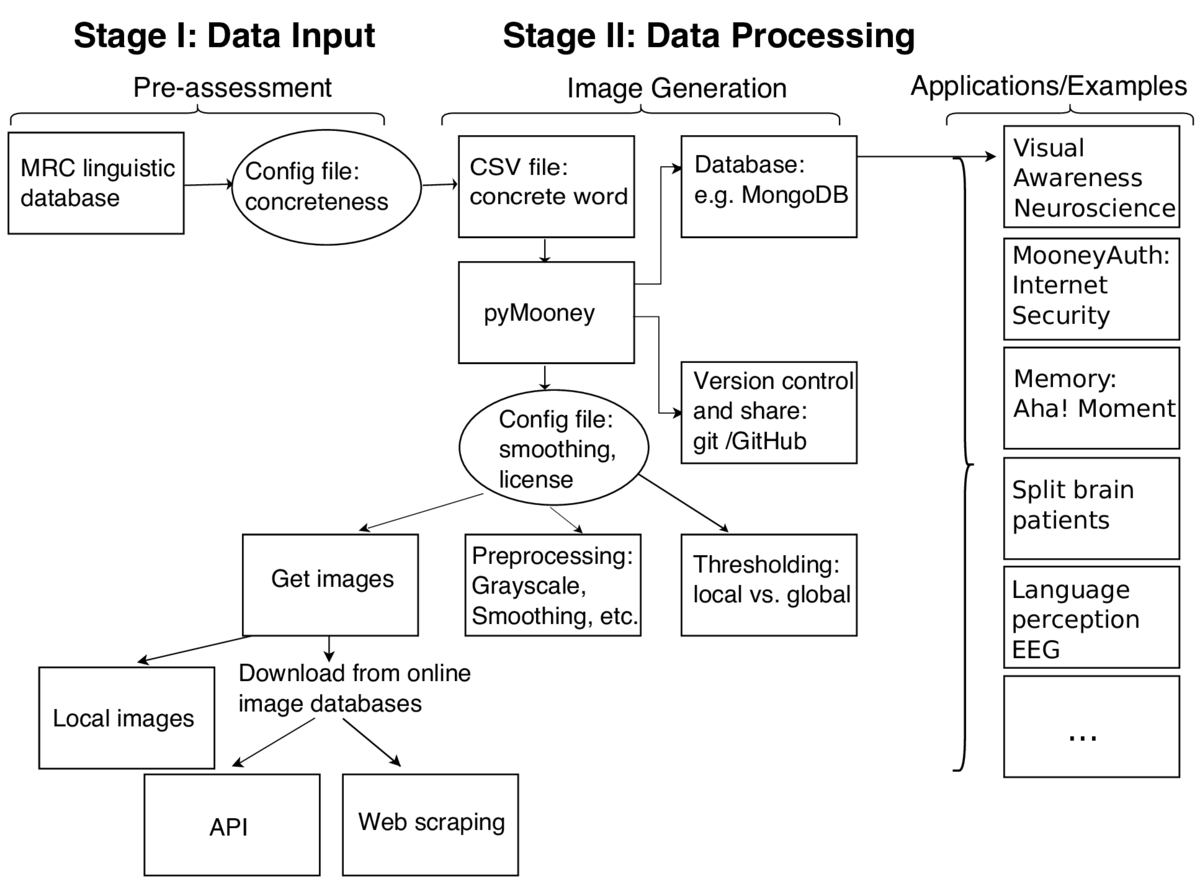 Generating two-tone, Mooney images starts with a selection of concrete words. There is a database called MRC Psycholinguistic Database where each word has been labeled as concrete or abstract, how frequently it is used, etc. From this database I selected 967 concrete words. The necessary parameters are saved in a config file (e.g. concreteness rating and imageability rating between 550 and 700). These concrete words are saved in a CSV file. Using these concrete words as image search tags I downloaded real-world images from an online image database (e.g. Flickr, or Google images) in an automated fashion using the custom written pyMooney python package. This package is based on a python API (Flickr API) and the scikit-image library. Each project needs to have a config file that specifies whether the Mooney images are created based on images that are stored locally or whether the images should first be downloaded from an image database. If images are downloaded from an online resource licensing information needs to be set in the same config file. Using a smoothing and thresholding process (Otsu, 1979) and prescreening of images, I created a database of 330 two-tone images for the pilot image selection experiment. These images can be stored in a document oriented database (e.g. MongoDB). A database has the advantage that information such as what preprocessing steps have been applied, what license information an images has, what is the average reaction time of the images in specific experiments etc. can be stored among the images. In addition images can be searched and selected according to this information. In this pilot experiment human subjects were presented with the two-tone, Mooney image and were asked to indicate the time when they recognized the hidden object in the image with a key press. They were further asked to label the name of the object that they think they recognized.
Generating two-tone, Mooney images starts with a selection of concrete words. There is a database called MRC Psycholinguistic Database where each word has been labeled as concrete or abstract, how frequently it is used, etc. From this database I selected 967 concrete words. The necessary parameters are saved in a config file (e.g. concreteness rating and imageability rating between 550 and 700). These concrete words are saved in a CSV file. Using these concrete words as image search tags I downloaded real-world images from an online image database (e.g. Flickr, or Google images) in an automated fashion using the custom written pyMooney python package. This package is based on a python API (Flickr API) and the scikit-image library. Each project needs to have a config file that specifies whether the Mooney images are created based on images that are stored locally or whether the images should first be downloaded from an image database. If images are downloaded from an online resource licensing information needs to be set in the same config file. Using a smoothing and thresholding process (Otsu, 1979) and prescreening of images, I created a database of 330 two-tone images for the pilot image selection experiment. These images can be stored in a document oriented database (e.g. MongoDB). A database has the advantage that information such as what preprocessing steps have been applied, what license information an images has, what is the average reaction time of the images in specific experiments etc. can be stored among the images. In addition images can be searched and selected according to this information. In this pilot experiment human subjects were presented with the two-tone, Mooney image and were asked to indicate the time when they recognized the hidden object in the image with a key press. They were further asked to label the name of the object that they think they recognized.
In our functional magnetic resonance imaging (fMRI) experiment we were interested in the question how brain activity changes when subject's recognize the hidden object versus when they not. The two-tone images do not change over the course of the presentation but a subject's perception change over time, and this moment in recognition is associated with a change in brain activity, which we wanted to capture. FMRI image acquisition is relatively slow (every 2 seconds). In addition, as fMRI scans are costly, we are limited by time. Hence, for this fMRI experiment I selected 120 Mooney images (resized to have a 400 x 400 pixel size) that were recognized within 4-10 seconds in the pilot experiment.
The code is written in Python and is available on GitHub.
Pain points
When images are downloaded from an online resource copyright issues can emerge. This can be avoided by downloading images that are licenced as Creative Common. This change is reflected on the latest version controlled pyMooney code and new images can be created with such criteria.
Key benefits
The main benefit of this part of a larger experiment is that these images are now available for further research. The images are currently used in 30 different experiments ranging from clinical set-ups, human memory experiments (Kizilirmak, Silva, Imamoglu, & Richardson-Klavehn, 2016), vision research, and latest internet security applications (Castelluccia, Duermuth, Golla, & Deniz, 2017).
Key tools
Image processing libraries are important building blocks of this particular case study. In this case the open source python library scikit-image was used. In addition online image database APIs such as FlickrAPI are essential.
Questions
What does "reproducibility" mean to you?
In the context of this study reproducibility means that given the code and a database of images, a new researcher can have access to the images and use the code that was used to create the same images or new images with the same parameters. These images can then be used to (i) replicate the current findings, (ii) create new questions potentially based on the current findings.
Why do you think that reproducibility in your domain is important?
I think without reproducible research we waste a lot of professinal time and research money. In my own domain, and in direct connection to this case study I can outline an example. When I came upon the two-tone images in the literature, I contacted several groups with a request to use their images (of course I mentioned that I will properly cite their work), who had used similar images for other behavioral or neuroscience experiments. Unfortunately, the images that these groups used were very limited in number but nevertheless, I never got a response from these groups. Hence, in order to start my experiment I had to spend almost a year to create the new stimuli.
How or where did you learn about reproducibility?
This was a self taught practice. Hence, the stages described here still has some space for improvement, which I will elaborate further below.
What do you see as the major challenges to doing reproducible research in your domain, and do you have any suggestions?
In neuroscience the main pitfalls are sharing human subject data and the resistance in the field to share code or data. The majority of the community does not have an open science mind set. Researchers are afraid that someone else can conduct an experiment before they publish their results. Even if they published some results they are sometimes not willing to share the data as they think they can continue to ask new questions using the very same data.
What do you view as the major incentives for doing reproducible research?
I think reproducible research allows faster progress in a researcher's own domain and makes interdisciplinary projects possible. To see that your own research is further used not only in your own domain but also across domains is very rewarding. It opens up possibilites for new collaborations. For example, I collaborated in two new projects that recently got published by making my stimulus available (Kizilirmak et al., 2016, Castelluccia et al. (2017)).
References
Castelluccia, C., Duermuth, M., Golla, M., & Deniz, F. (2017). Towards implicit visual memory-based authentication. In Network and distributed system security symposium (ndss).
Imamoglu, F., Kahnt, T., Koch, C., & Haynes, J.-D. (2013). Changes in functional connectivity support conscious object recognition. Neuroimage, 63, 1909–1917.
Kizilirmak, J. M., Silva, J. G. G. da, Imamoglu, F., & Richardson-Klavehn, A. (2016). Generation and the subjective feeling of “aha!” are independently related to learning from insight. Psychological Research, 80(6), 1059–1074.
Otsu, N. (1979). A threshold selection method from gray-level histograms. IEEE Trans. Sys., Man., Cyber., 9(1), 62–66.