Using Observational Data and Numerical Modeling to make Scientific Discoveries in Climate Science
David Holland and Denise Holland
My name is David Holland. I am a Professor of Mathematics and Atmosphere Ocean Science at New York University's Courant Institute. I study global sea level rise in a changing climate, specifically, how changes in global weather patterns affect the melting of the great ice sheets, with Denise Holland, who is the Field and Logistics Manager for our field research program.
Workflow
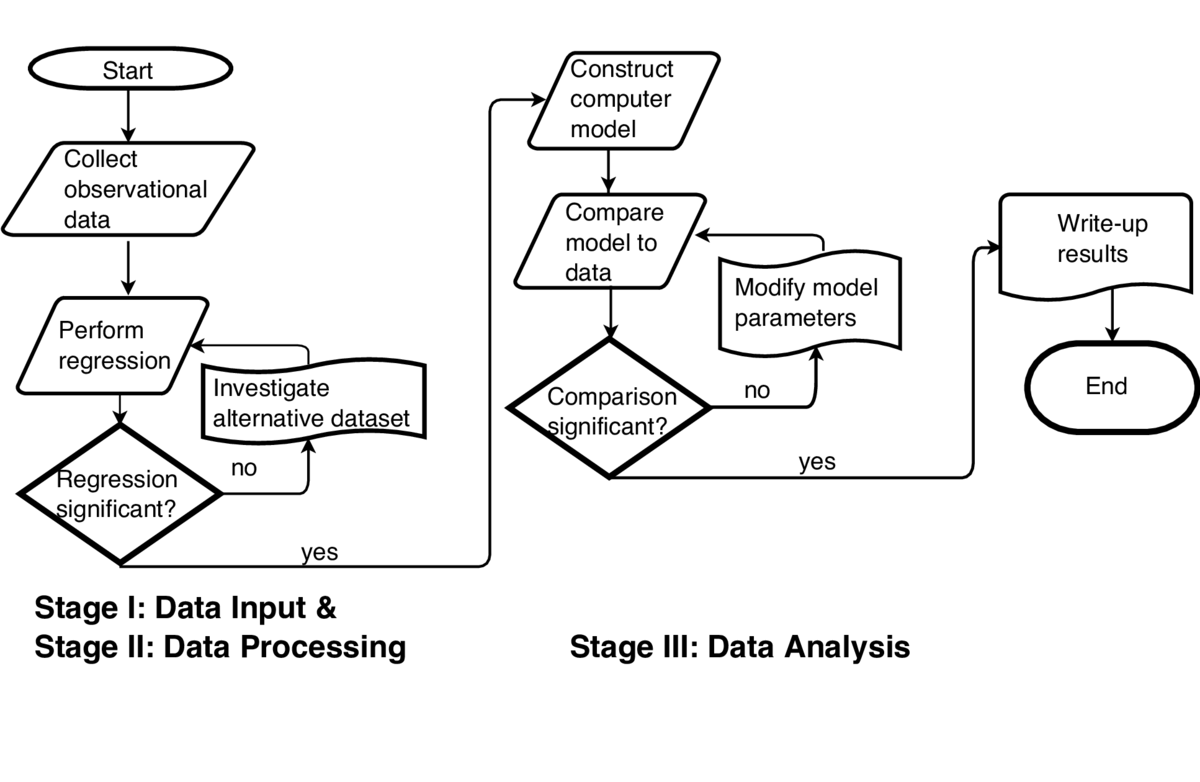 The goal of our workflow design is to use observations and computer models to make new discoveries about the natural environment particularly in the context of climate change. The approach we take in our algorithm design is to generally always look for an interesting phenomena in the observational record first. If we find it there, then we generally proceed to try to simulate it in a computer model as an independent check on the physical plausibility of the phenomena in question. In this very specific workflow, we will illustrate our approach for the particular question: does the North Atlantic Ocean drive climate change in Western Antarctica?
The goal of our workflow design is to use observations and computer models to make new discoveries about the natural environment particularly in the context of climate change. The approach we take in our algorithm design is to generally always look for an interesting phenomena in the observational record first. If we find it there, then we generally proceed to try to simulate it in a computer model as an independent check on the physical plausibility of the phenomena in question. In this very specific workflow, we will illustrate our approach for the particular question: does the North Atlantic Ocean drive climate change in Western Antarctica?
The very first step in our workflow is to collect all available observational data of North Atlantic Ocean surface temperatures going back in time as far as is possible. The more spatial and temporal data we have, the more robust the results will be. On occasion, different datasets can be contradictory or inconsistent. In this case, we have to make subjective decisions if one dataset is better than the other. If we cannot make this decision, we cannot proceed and the algorithm has to terminate. On the other hand, if two different datasets agree, then we proceed with greater confidence of the quality of our input data. In our study, our analysis of the North Atlantic temperature data strongly showed us that there exists a 60 year period oscillation in the surface temperature in a broad pattern that covers the entire North Atlantic. This is known as the Atlantic Multi-decadal Oscillation (AMO). This result has been previously found by other researchers so our very first step has not only given us confidence in what we are doing, but also reproduces a result from other researchers. All of our science research tends to in fact work this way in the sense that our new findings tend to be built on reproducing previous work by others and then extending that into new, unchartered research areas.
The next dataset we investigate is the surface winds over the Western Antarctic region. In exact analogy with the processing of the North Atlantic surface temperatures above, we proceed here to look for long term trends in winds. We find such a trend and it matches with the North Atlantic Ocean surface temperatures, suggesting one is causing the other. We claim such a relation based on a formal regression calculation which shows our finding is statistically significant but still does not explain which is the cause and which is the effect.
The next step in the algorithm is to employ a physically based numerical model of the global climate system. Using such a model, we can impose the observed North Atlantic Ocean surface temperatures in the model, and the model can simulate the response of the global atmosphere to this imposed ocean forcing. We carry out the simulation and we find that North Atlantic Ocean temperature oscillations drive wind circulation anomalies in Western Antarctica. This is a very surprising, non-intuitive result. We also try to model in the opposite sense, and impose surface wind anomalies in Western Antarctica to see if they drive ocean temperature anomalies in the North Atlantic. The simulation showed that this does not happen. This gives us some confidence to conclude that the direction of flow of climate change is from the North Atlantic to West Antarctica.
At this final stage, having made a new discovery in two independent manners, one purely observational and one purely computer modeling, we are ready to report our findings to the scientific community. This involves a rigorous peer-review process that imposes a number of reproducibility requirements. A section of the manuscript must be devoted to explaining where all datasets are located and how a reviewer or future reader could access the same datasets we use. Likewise, we are required to describe the computer model we used and how a future researcher can access the same model. While the main scientific article is relatively brief (about 4 printed pages), giving the reader the essential information on what we found and how we found it, we also write a supplementary materials section. This is an exhaustive description of each step we took with our observations and our modeling.
The original data sources that we used for ocean temperatures and atmospheric winds are on-line and available through national climate data repositories. The numerical modeling code is available on-line through national climate modeling centers. The regression calculations and the numerical simulations we preformed are very large and are not stored on-line but are archived at NYHU on hard disks off-line. The regression code is standard and available at many repositories such as part of Matlab. It is well documented, well tested, with many examples. The numerical climate code is used by a large number of people, it is well documented, well tested, with many examples. There are no restrictions on other researchers replicating or confirming our work. We warmly welcome such activity.
As mentioned in our published paper, there is a supplementary document that includes details about the data processing workflow. There is not the actual computer scripts used to perform the regressions nor those to run the numerical climate model. These could in fact be put on-line if there was a repository for such information. However, in our estimation, if someone was to try to reproduce our research it would probably be more natural for them to write their own scripts as this has the additional benefit that they might not fall into any error we may have accidentally introduced in our scripts.
Our published work is citeable as: Li, Xichen, David M. Holland, Edwin P. Gerber, and Changhyun Yoo. "Impacts of the north and tropical Atlantic Ocean on the Antarctic Peninsula and sea ice." Nature 505, no. 7484 (2014): 538-542.
Pain points
The most difficult part of reproducing these results is the sheer volume of the datasets involved and the amount of computational storage and time required to complete all these calculations. Transferring large volumes of data from super computers (where the main code is run) to personal computers (where the analysis is generally performed) is an onerous and time consuming task with many failure points. Often data transfer is incomplete, storage disks break or fail, and weeks or months of research time is lost. In such case, one has to simply go back to the start and begin again.
Key benefits
Our approach of independently using observational data and modeling is a stronger approach than that of just using one or the other. Our approach also is to abandon findings that are contradictory between independent observational datasets as this suggests that the data is of inadequate quality to proceed further with any analysis or conclusion. In other words, if you find something interesting in analysis of one dataset, but not in another similar one, despite the temptation to proceed with the interesting finding, one must acknowledge that the contradiction prevents moving forward.
Key tools
We have nothing special to report here but are aware of efforts in the computer science community to better track the workflow stages of a research project. In our project, such software would have been beneficial in that our workflow algorithm could be online and a user could click through it and find the scripts and datasets and models we used.
Questions
What does "reproducibility" mean to you?
"Reproducibility" for me means that someone, anyone, could read my published research, then take the datasets I have archived on the web and use them to reproduce the results I had in my published paper.
Reproducibility is at the heart of natural science. Without being able to perform an experiment and achieve a certain result, and then to have an independent scientist reproduce the same result, the research finding is murky. Our publications in high-profile journals, such as Science and Nature, demand that we include a methods section in our papers, as well as carefully document the location of all our datasets on the internet. Some of the research code developed requires years to master. Scientific funding and the number of scientists available to do the work is finite. Therefore not every scientific result can, or should be reproduced. The most important, paradigm shifting results should, however, be reproduced. In the case of climate science, important decisions by world leaders rely on scientific findings. These finding must be robust and reproducible in order to guide energy use policy. In our study, we reached the same conclusion using both purely observational data and then independently through a computer simulation of the same phenomenon. Finding the same result in two completely independent manners gives us confidence in our findings.